
Collect unbiased data utilizing these four types of random sampling techniques: systematic, stratified, cluster, and simple random sampling.
Written by Terence Shin
Random sampling means choosing a subset of a larger population where each sample has an equal probability of being chosen. Random samples are used in statistical and scientific research to reduce sampling bias and get sample data that is generally representative of a population, which help form unbiased conclusions.
Random sampling simply describes a state wherein every element in a population has an equal chance of being chosen for the sample. Sounds simple, right? Well, it’s a lot easier said than done because you must consider a lot of logistics in order to minimize bias.
If you’re a data scientist and want to develop models, or a researcher who wants to analyze a population, you need data. And if you need data, someone needs to collect that data. And if someone is collecting data, they need to make sure that it isn’t biased or it will be extremely costly in the long run.
Therefore, if you want to collect unbiased data and create more accurate data models, then you need to know about random sampling and how it works.
There are four main types of random sampling techniques: simple random sampling, stratified random sampling, cluster random sampling and systematic random sampling. Each is used for different sampling situations.
Simple random sampling requires the use of randomly generated numbers to choose a sample. More specifically, it initially requires a sampling frame, which is a list or database of all members of a population. You can then randomly generate a number for each element, using Excel for example, and take the first n number of samples that you require.
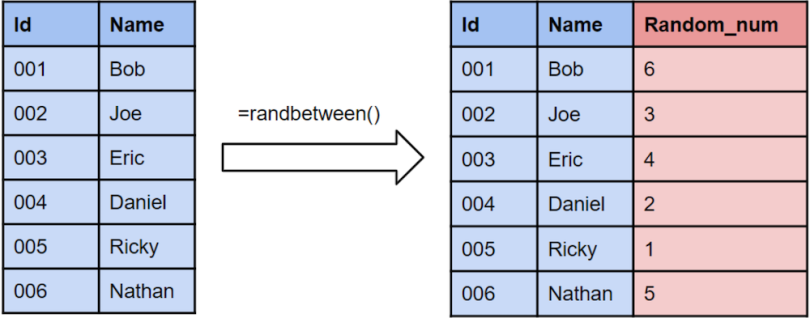
To give an example, imagine the table on the right was your sampling frame. Using software like Excel, you can then generate random numbers for each element in the sampling frame. If you need a sample size of three, then you would take the samples with the random numbers from one to three.
Stratified random sampling involves dividing a population into groups with similar attributes and randomly sampling each group.
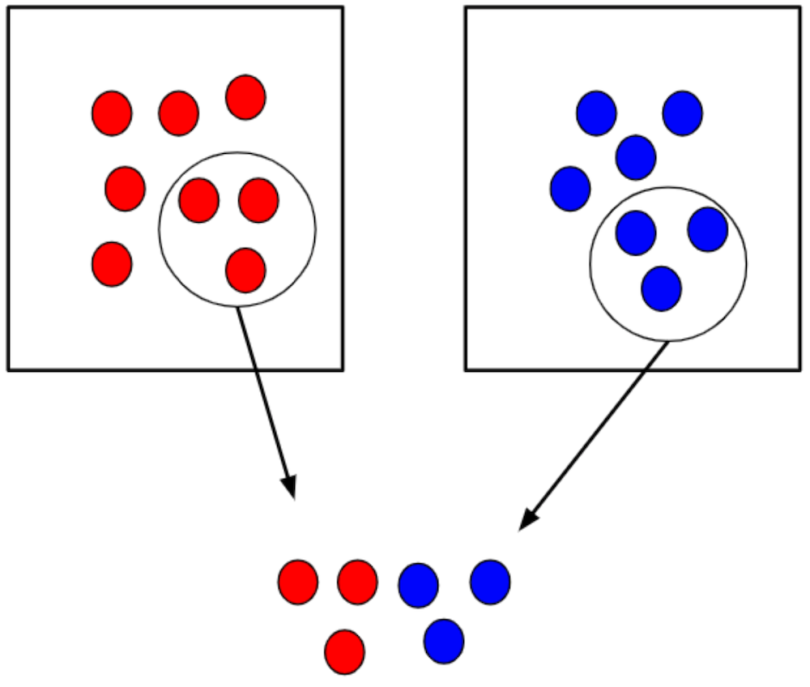
This method ensures that different segments in a population are equally represented. To give an example, imagine a survey is conducted at a school to determine overall satisfaction. Here, stratified random sampling can equally represent the opinions of students in each department.
Cluster sampling starts by dividing a population into groups or clusters. What makes this different from stratified sampling is that each cluster must be representative of the larger population. Then, you randomly select entire clusters to sample.
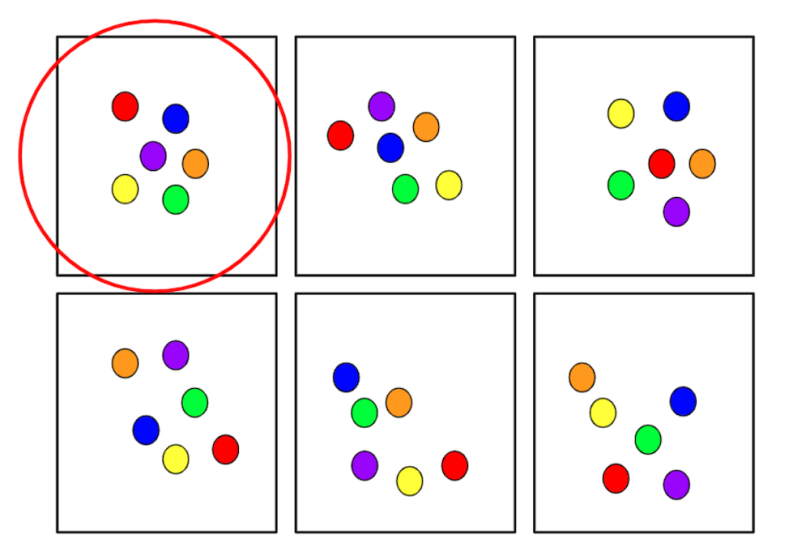
For example, if a school had five different eighth grade classes, cluster random sampling means any one class would serve as a sample.
Systematic random sampling is a common technique in which you sample every kth element. For example, if you were conducting surveys at a mall, you might survey every 100th person that walks in.
If you have a sampling frame, then you would divide the size of the frame, N, by the desired sample size, n, to get the index number, k. You would then choose every kth element in the frame to create your sample.
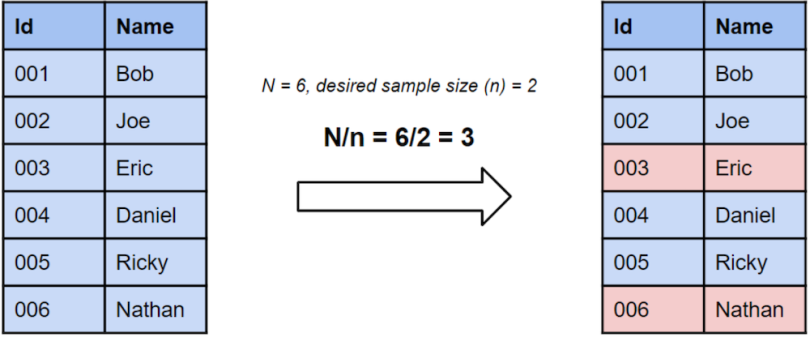
Using the same charts from the first example, if we wanted a sample size of two this time, then we would take every third row in the sampling frame.
Random sampling involves collecting a subset of samples from a population in a way where each sample has an equal chance of being chosen. Random samples are used to ensure a sample adequately represents the larger population and to minimize sampling bias in research results.
The 4 main types of random sampling are:
An example of a random sample would be randomly choosing the names of 10 people from a hat containing the names from a group of 100 people.